Building a Better, Simpler Model of Running Back Success
For several years, I’ve been publishing predictions of NFL rookie success odds for wide receivers and running backs over at 4for4. The wide receiver model, in particular, has an exceptional track record of identifying undervalued rookie receivers.
While the predictions incorporate the output of a more sophisticated machine learning model (a Support Vector Machine), the core of the predictions come from an incredibly simple logistic regression model built on just two metrics about the player: what draft pick they were and how much of their college team’s yards were they responsible for over their full career. It turns out that you can identify undervalued receivers pretty well with just those two variables because fantasy drafters frequently undervalue them.
The results for the running back (RB) model, on the other hand, have been less satisfactory. The best logistic regression models I could find required 3–4 variables and still were not as good as the 2-variable receiver model. An SVM was no better. A couple years ago, I built a model that first put running backs into clusters and then applied simpler logistic regression models within each cluster. That improved results, but still did not match the receiver model in accuracy (let alone simplicity!).
Given that, I put some more time in this spring trying to come up with a better model using what I’ve learned in recent years. In particular, I wanted to see if using over-parameterized models could improve the results.
Over-Parameterization in RB Models
As I’ve discussed before, my default strategy nowadays is to build an over-parameterized model, that is, a model whose number of tunable parameters exceeds the number of examples it was trained on. Despite having more ability to “over-fit” the training data, such models can (and usually do) have reliably good performance.
With running backs, it is especially easy to over-parameterize. There have been fewer than 400 drafted running backs since 2001. (It’s hard to go back much further than that because the nature of the game changes over time.) With fewer than 400 examples, it doesn’t take much work to build a model with more parameters than examples.
With tabular data like this, the natural option would be a Random Forest model. Even if we restrict the individual trees to 4 just nodes, a random forest consisting of 1000 trees would be over-parameterized. For this problem, such models do indeed give reliably, solid performance. Unfortunately, however, they do not give performance on par with my simple wide receiver model.
Choosing Metrics for the RB Model
One aspect of predicting rookie performance that is probably unusual for machine learning is that the number of metrics used to predict success (the “features” of the examples) exceeds the number of training examples.
As noted above, we have fewer than 400 examples on which to train an RB model. Meanwhile, Peter Howard’s database includes over 400 different metrics that have been calculated to try to predict success. My own database has over 100 more. Having more metrics for each example than total number of examples is, I think, fairly unusual. It also seems to make the problem quite a bit more complicated.
One strong clue that wouldn’t be so simple as just building a standard Random Forest model came early on. After sorting all of Peter Howards metrics by correlation with future success, I decided to see how valuable the best metric was by building a second model without that metric included. Much to my surprise, the results were better! Removing from the data the individual metric that was best predicts future success gives a Random Forest model that is more, not less, accurate.
Pairing down the data to just the top 20 or so most predictive metrics (but without the single most predictive metric) improved results further. From this sort of experimentation, it became clear that, even with Random Forest models, metric selection would be important and that using fewer metrics generally worked better.
Fortunately, my own database was not so ill-behaved as Peter Howard’s. The most predictive metric in my database is draft pick, and removing that definitely makes results worse.
Results got better as I shrunk the number of metrics further. I ended up trying every choice of 3 metrics out of the top-25 most predictive ones. Interestingly, all of the best combinations shared the same two metrics: draft pick and age. Reducing to just those two metrics gave the best performance of all.
Understanding and Simplifying the Model
Now that the number of metrics (variables) in the model was small, I could start using pictures to try to understand the model better. I did the same thing most recently in this article, where it allowed us to get a handle on why value investing has underperformed in recent years.
Here are predictions of the 2-metric random forest model (with 1000 trees):

Two things stand out to me in this picture. First, the success odds decrease in a step-wise fashion as the pick increase, with clear drop-offs after certain picks (rather than, say, a slow and steady decrease as players are picked later and later). Second, age is largely just a cut-off: players that are 22.5 or so before their first NFL season get higher odds across the board than those who are older than 22.5.
Broadly speaking, the plot breaks the inputs up into about 10 regions based on pick and age, but within those regions, the predictions are relatively flat. For that reason, it seemed like I could summarize this model with a simple table that gave a single prediction for each of the 10 buckets as follows:
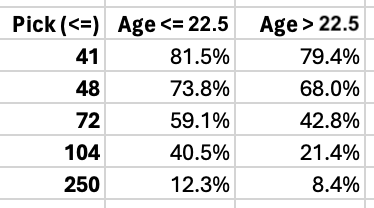
Surprisingly, this simple table is actually more accurate than the Random Forest that gave us the plot above! So this is the new model I settled on.
Conclusions
In the end, I got what I hoped for: a simple 2-variable running back model whose performance nearly matches that of the simple 2-variable model for wide receivers. Of course, I must not forget the only free lunch in machine learning is to build ensemble models, so while this will be the primarily model for this year’s predictions, I will also incorporate the clustered linear regression model, an SVM model, and a larger Random Forest model into the final predictions.
The journey to get this final model also reiterates the usefulness of the techniques we used along the way. Starting with an over-parameterized Random Forest model was a good idea once again. Drawing pictures of model predictions on small numbers of variables at a time once again led to useful insights.
What was new, this time, was that the end result of a path that worked through over-parameterized models eventually ended with something even simpler than linear regression: just a simple table. This shows that our default option of starting with over-parameterized models doesn’t preclude the possibility of ending up at the other extreme in the end.
